Graduated in electrical engineering, MBA, and specialization in artificial intelligence. Since 2008 working as engineer in telecommunications sector.
Curriculum vitae: English | Portuguese




Portfolio
Below are a few selected machine learning projects. These are independent works, and this portfolio is continuously evolving. Feel free to explore, or, if you prefer, visit my GitHub page.
Topics
Natural Language Processing
Decoding User Complaints: An Analysis using Mistral 7B SLM
Organizations face the critical task of analyzing diverse, complex user complaints. Accurate interpretation and response are key, with Large Language Models (LLMs) proving essential for efficient, automated complaint management and analysis.
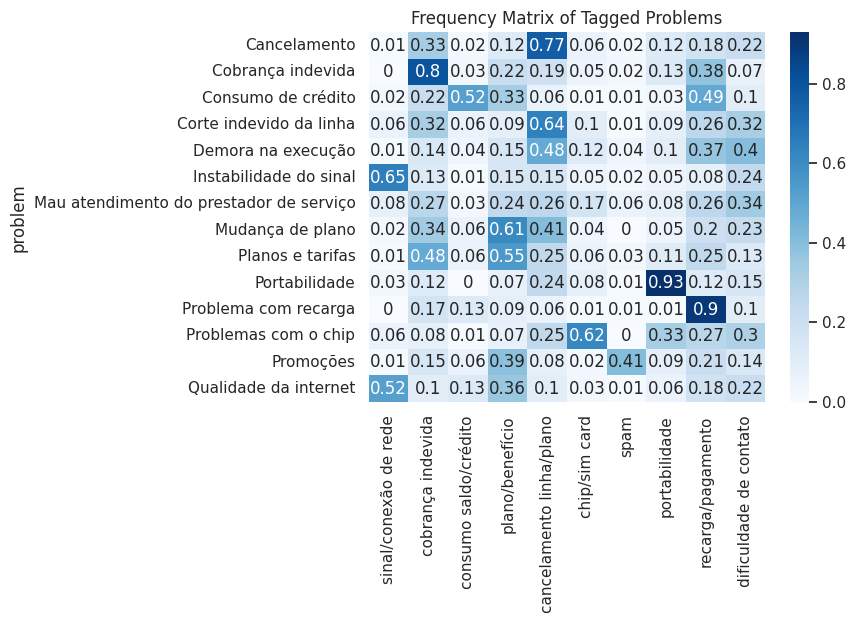
In this study, I developed a rapid and automated system using Mistral 7B SLM for categorizing user complaints into relevant categories. This approach offers insights into customer concerns, thereby enhancing organizational response strategies. Read full article in English and Portuguese.
| pandas | numpy | sklearn | matplotlib | seaborn | selenium | beautifulsoup | transformers |
Sentiment Analysis
Sentiment analysis is a segment of machine learning that deciphers emotions within textual data. By employing sophisticated algorithms, it classifies text as positive, negative, or neutral, enabling invaluable insights across industries.
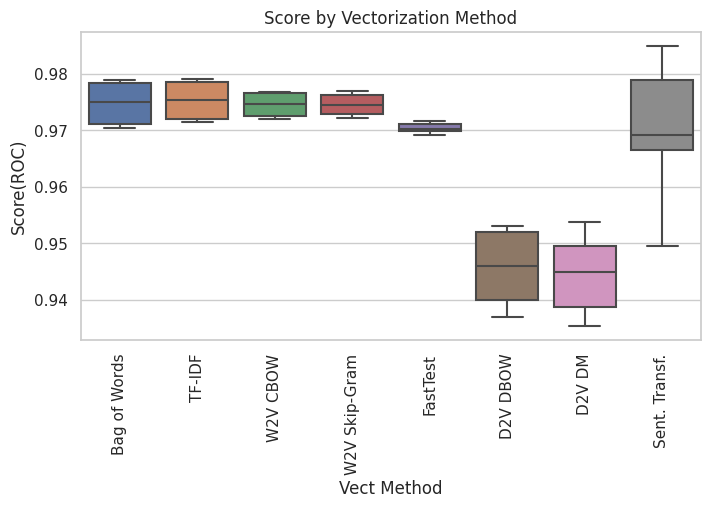
In this study, I measured the impact of different text pre-processing methodologies, such as stop word removal, lemmatization, and stemming in different types of word embedding, from the simplest ones like bag of words to transformers like BERT.
| nltk | spacy | pandas | numpy | sklearn | lightgbm | matplotlib | seaborn | gensim | torch | transformers | sentence_transformers |
Customer Complaint Analysis with Topic Modeling
Analyzing large datasets of customer complaint texts is a challenging and essential task for companies looking to improve the quality of their products and services. The diversity of words, topics, and sentiments expressed in such texts can overwhelm analysts. This is where topic modeling emerges as a valuable tool.
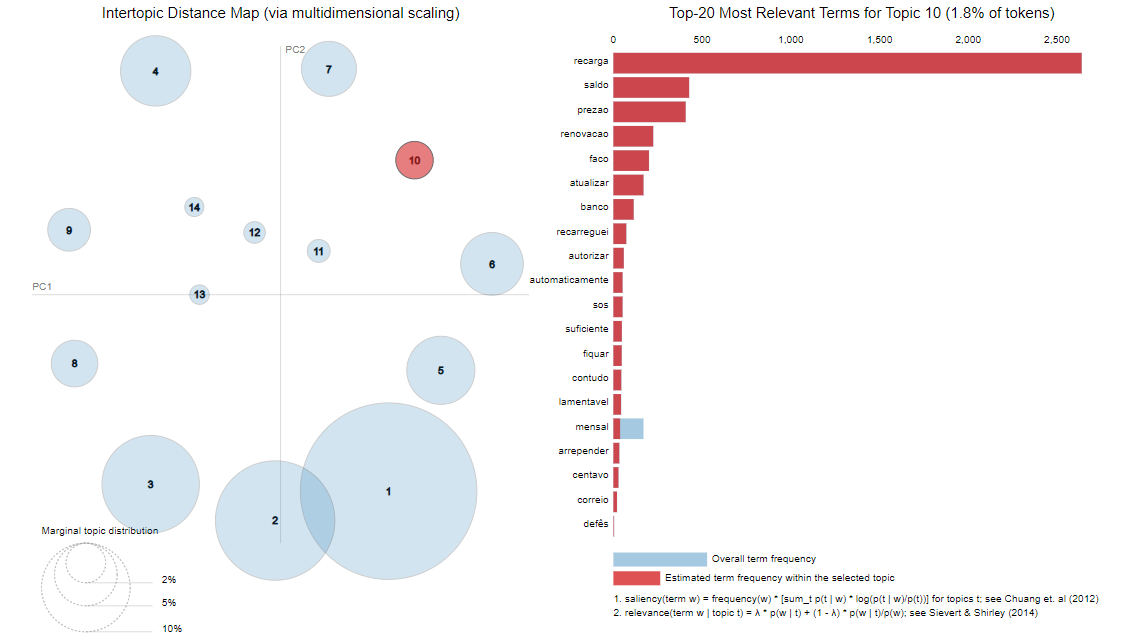
This work explores how topic modeling can be an effective solution for analyzing large customer complaint datasets, highlighting its applications and benefits.
| selenium | beautifulsoup | pandas | nltk | spacy | pyLDAvis | bertopic |
Recommender System
A recommender system is a class of algorithms and techniques used in information filtering and decision-making processes. Its main purpose is to provide personalized suggestions or recommendations to users for items they might be interested in.
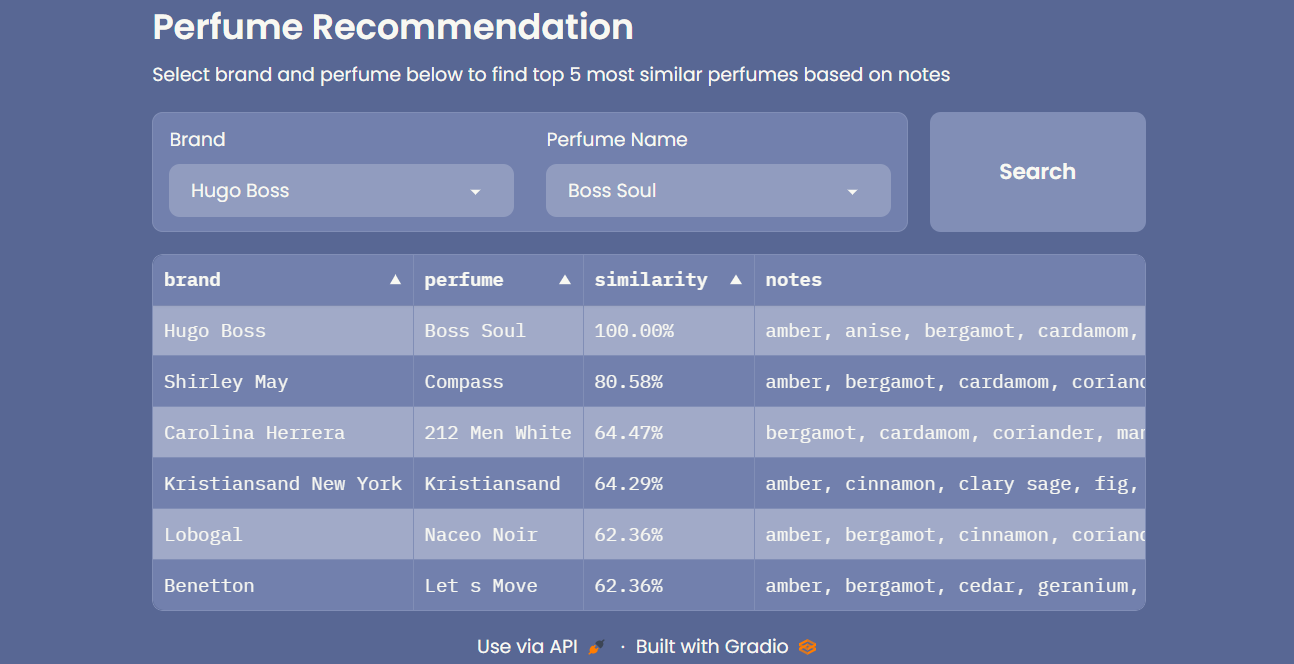
In this work, I created a perfume recommendation system built based on the scent description using bag-of-words and similarity search (cosine). Then a demo app was built and can be seen on Perfume Recommender App.
| pandas | numpy | sklearn | scipy | gradio |
Classification
Credit Risk
Credit scoring algorithms, which make a guess at the probability of default, are the methods banks use to determine whether or not a loan should be granted. In this Kaggle competition, participants were required to predict the probability that somebody would experience financial distress in the next two years.
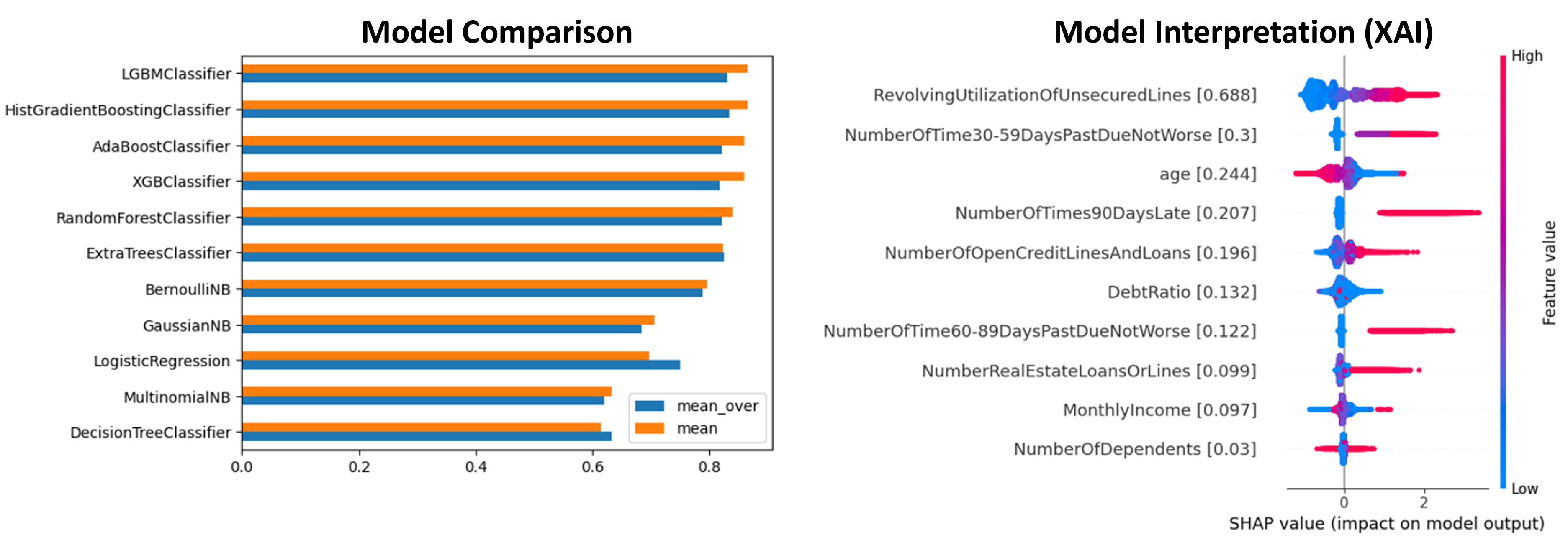
To tackle this problem, I implemented several models and compared them to find out which one got the best score (AUC). After fine-tuning the winner, I used SHAP to explain which features were most important to the model.
| pandas | numpy | matplotlib | sklearn | skopt | imblearn | shap | xgboost | lightgbm |
Time Series Forecasting
Traffic and Congestion Prediction on LTE Networks
A nationwide cellular mobile network contains tens of thousands of base stations. Estimating the traffic increment and consequent congestion of each of these elements can become an arduous and imprecise task, and can lead to incorrect investment decisions.
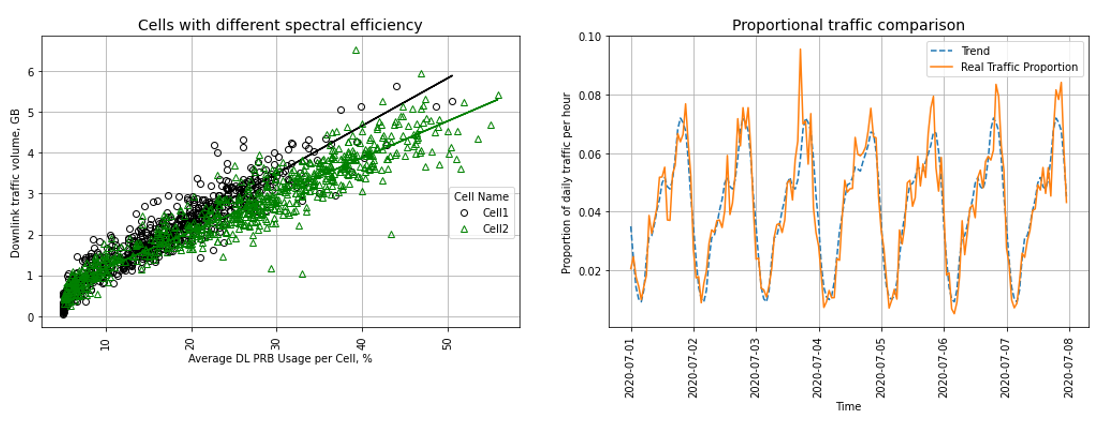
To address this business problem, I replicated the work done by D. Chmieliauskas and D. Guršnys (2019) with some improvements. First, Facebook Prophet was used to generate a time series forecast for the data traffic, and then a linear regression between traffic volume and cell resource usage was performed to define the congestion threshold. The purpose of this work was to provide a replicable code for paperswithcode.com
| prophet | pandas | sklearn | scipy | numpy | matplotlib | seaborn |
Causal Inference
Translation of the book Causal Inference for The Brave and True
This work is an authorized translation of the open-source book titled Causal Inference for The Brave and True originally authored in English by Matheus Facure. This translation aims to contribute to the Portuguese-speaking community that may not be very familiar with English, providing accessible material for those interested in the subject.
You can check the Brazilian Portuguese version here. I had a lot of fun and learned a great deal while translating this book. I hope you enjoy and learn as well! Best wishes and happy studying!
Local versus Global Shocks in the Brazilian Stock Market: Evidence from Synthetic Control
In many real-world settings, such as public policy interventions, economic shocks, regional marketing campaigns, or institutional events, identifying credible causal effects is challenging due to the absence of a valid counterfactual. In such settings, the synthetic control method can provide a data-driven approach to approximate the counterfactual by constructing a weighted combination of comparable units, enabling the estimation of the causal effect of unique or infrequent interventions.
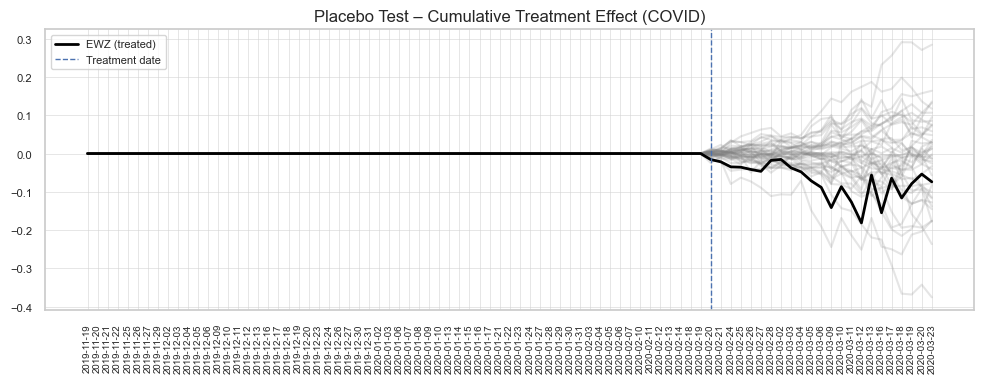
In this article, I use synthetic control method, to identify whether a given fluctuation in the Brazilian stock market was intrinsic or merely another routine movement of the global market. You can read the full article in English here and in Portuguese here.